
5 Reasons to Add Observability to your Workflow

In the IT world, Observability has been the answer to managing the chaos of users and applications in distributed systems. According to Cloud Data Insights, 90% of IT professionals believe that observability is important and strategic to their business.
For good reason: observability solutions provide visibility, event tracing, and context, which are key in identifying/finding root causes and resolving issues.
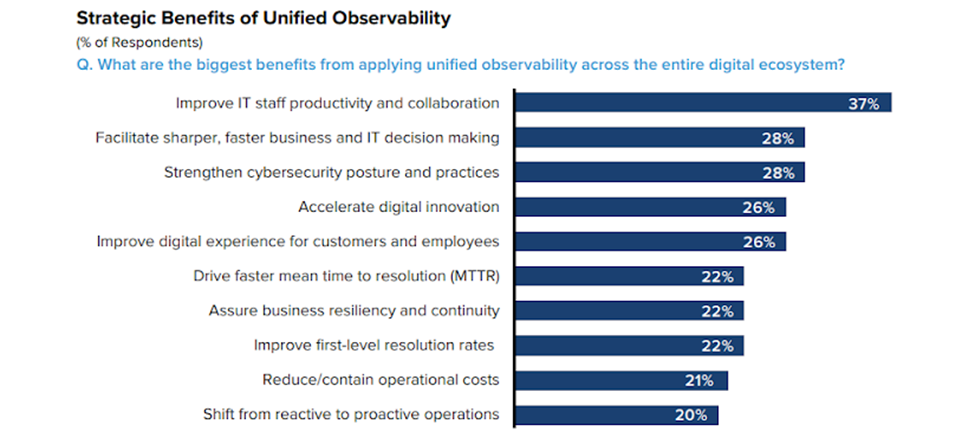
Image source: IDC WW Unified Observability Survey, 2022
However, unlike the IT industry, broadcasters have been slow to adopt observability even whilst taking steps into all-IP workflows.
Crucial network problems take 2nd and 3rd place to equipment selection, traditional monitoring, and visual content inspection.
In this post, we will take a look at the benefits of observability and network intelligence for the broadcast industry and how they are being used to increase agility, reduce operational costs, and make informed networking workflows.
Observability as a game changer for broadcast operations
Observability can provide measurable benefits to any system. The following factors contribute to its ROI for infrastructure and organizations:
1. Performance improvement over time –– finding root causes quickly
Networks are dynamic in nature controlled by external traffic patterns and routing decisions predominantly outside of an organization’s control. Consequently, there are many points of failure.
Organizations are forced to spend time-consuming resources identifying the root causes of problems.
Try to remember the last time your team experienced a network problem: how much time did it take to identify that it was a network issue and not the source or destination? How many people needed to get involved in the process? How much time did it take to identify the actual source?
With network observability, an engineer can detect and troubleshoot the root cause in a matter of minutes instead of days, resulting in fewer outages and improved uptime.
Adding Observability to the standard workflow presents all of the necessary information to IT and broadcast engineers on a single pane of glass including alerts, notifications, comparison charts, and a full operational map of the video network. This in turn streamlines and reduces time to resolution by order of magnitudes.
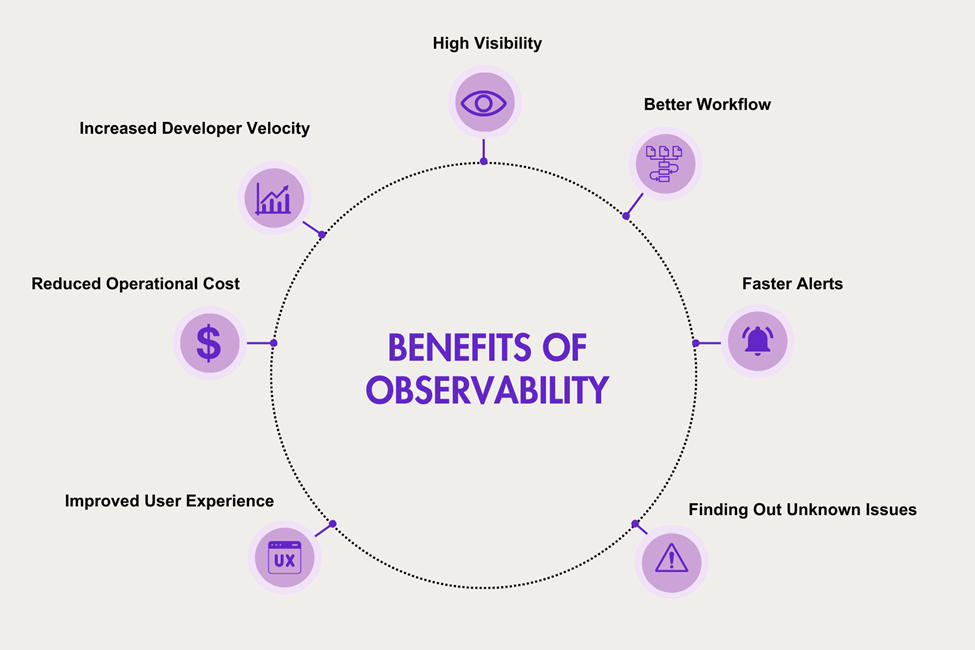
Image source: AlvaLinks
Enhanced serviceability and stability lead to better SLAs and continuous service. When correlated with other egress notifications, observability tools can detect and correlate network issues against external events and reports massively improving service performance. This translates into reduced operational costs and longer-term contracts.
Already broadly adopted by the IT and many other industries, the concept of observability has proven time and again its value in improving performance and SLA management. However, while the need for Broadcasters is tangible, no solution or tool was found to fit their intricate needs and challenges – Alvalinks technology overcomes this and is dedicated to the complexities of video networking.
A proactive network intelligence tool, such as AlvaLinks, can scan the network topology, discover and test every HOP, measure end-to-end delivery, and collect real-time statistics dedicated to video.
2. Saving operational costs through MTTR
It’s no secret that modern video delivery networks are prone to issues such as display and frame freezes. To ensure end-viewers are not impacted, most companies use a multi-network path (A + B) and run cloud operations as two or more redundant services. It’s necessary to monitor each network and service reach to select the best one every time.
Network-wide observability enables broadcasters to identify and resolve issues in real-time: from packet loss, to jitter, and latency, or even the presence of other operators’ streams and applications that might impact service.
Standard observability includes 3 main pillars: metrics, logs, and traces, but it’s important to add a 4th one––proactive testing––at a high sampling rate to understand the network impact on service.

Image source: AlvaLinks
All four of these pillars work together to give the operator and organization a 360-degree view of the service and end-to-end delivery. Once an event is triggered, the user can see both historical and real-time information, and correlate the event to network issues.
For example, a packet loss burst may be due to a congested hop on a route or route change; an SRT receiver experiencing buffer depletion can be traced to jitter, latency, or route change issues.
Without a network observability solution, it’s challenging to find the problem, let alone resolve the issue. For example, with Alvalinks, customers were able to trace MPLS-related issues that were hidden out of sight for several months.
Why is MTTR so important?
IT and Network issues lead to loss of revenue, loss of reputation, and create a deficit in a company’s bottom line.
Each time a new problem surfaces, the broadcast and IT teams must divert attention from what they are doing and address the issue at hand.
This might require reaching out and troubleshooting with equipment and service vendors or network service providers until the problem is identified and resolved. The time spent away from business-related tasks can add up quickly.
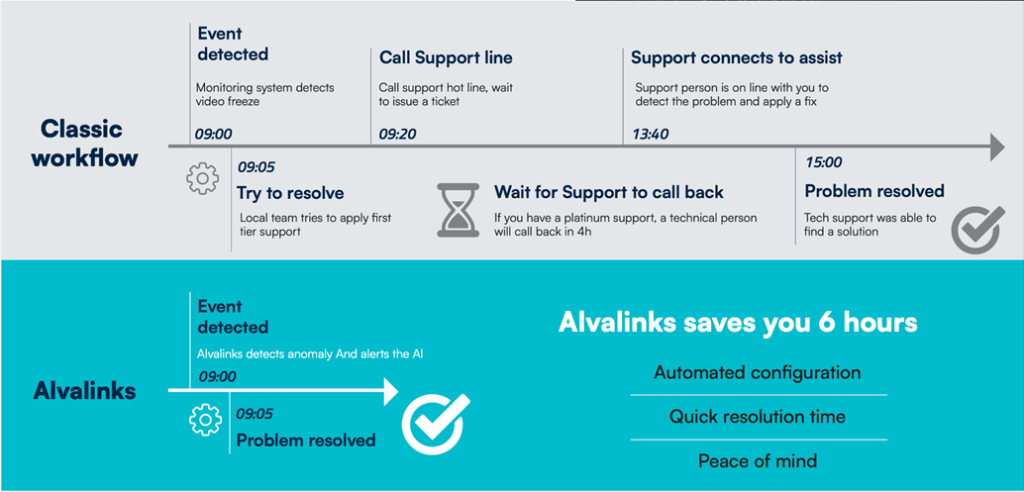
Image source: AlvaLinks
According to Splunk, organizations that adopted Observability have reported up to a 95% reduction in MTTR, and a saved an average of $2M million over three years.
3. Prevent incidents, prevent stress
Observability not only enables teams to respond to issues quickly, but it helps prevent them as well. This is especially true for groups following an observability-driven approach.
Legacy monitoring workflows tend to look at the egress of video outputs to detect issues such as compression errors, macroblocks, sound levels, the resulting frame freeze, tilling, black frames, and more.
Network intelligence observability adds the network into play and allows for a better and faster system view from source to destination. It analyzes the entire system and all its outputs to make sure everything is working as expected.
As mentioned, operators can set up alarms and event notifications when certain thresholds are reached notifying them as soon as a system shows the first sign of unexpected behavior. Oftentimes, this is enough to address the problem and to fix the issue before it escalates into a full-fledged incident.
According to Gartner, and reported by other sources, the average cost of IT downtime is $5,600 per minute. Studies have shown that organizations that have adopted observability solutions, and proactive notifications, have reduced overall incidents by up to 50% and the time to fix issues by 75%. This quickly amounts tomillions per year in savings.
4. Reducing travel cost and carbon footprint
A video delivery intelligence tool, such as AlvaLinks, can measure network behavior before a Live event goes on-air eliminating the need for complex travel.
Network behavior can be identified at different streaming bitrates or can be used in a new service introduction mode. This is critical in assessing the network capability to support a streaming service and fine-tune the streaming buffer configuration for latency, RTT, and jitter.
For live broadcast operations, if a team does not need to be on-site in advance this can save tens, or hundreds, of thousands of dollars in travel and accommodations per year. The carbon and waste footprints are minimized by not needing to fly, drive, or travel.
For example, an Alvalinks customer reported that major league sporting coverage during the season can amount to $500K to 600K in accommodations per season of one league.
5. Directly increasing customer value
Adding network delivery intelligence and observability has become a key differentiator for organizations’ operations, but also contributes to customer satisfaction.
For example, delivery intelligence elevates customer experiences, brand perception, and innovation. Streaming providers that are more agile and faster to react will be chosen against slow-moving competitors.
Shorter time to customer value
Pushing IP workflows to the cloud will keep companies up-to-date with technology and innovation, and more importantly, business agility. However, these new workflows add complexities among network, cloud, equipment and playout functions.
Comprehensive observability tools provide testing and emulation to understand and troubleshoot how the systems perform together before even going live.
Prior to network delivery intelligence and observability, teams had to be knowledgeable on a wide array of technical domains, and still experienced challenges in pinpointing issues.
However, network observability provides fast, accurate, and automated feedback to operators giving engineers the confidence to roll out features as soon as they are ready, utilize the feedback, and quickly prioritize and resolve issues.
Improved customer experiences
According to PWC, 80% of customers consider speed, convenience, and quality of service as top values from a product or service. They are willing to spend 16% more on premium services.
In almost every industry, businesses that fail to adhere to high customer expectations face consequences. With so much at stake, delivering top-notch digital experiences has become the primary objective of every broadcaster, and for those with complex software infrastructures, observability is a beacon.
Without proactive observability, it’s common for glitches to go unnoticed as static monitoring systems are not paying attention to the needed parameters, negatively impacting the customer experience.
Observability combs out all anomalies and helps teams focus their engineering efforts toward the best digital experiences. They can quickly trace the issues to faulty configurations, equipment, network elements, or devices, and resolve them.
Conclusion and using observability as an innovation platform
It’s important for businesses to innovate, but innovating in a rapidly evolving ecosystem is no easy feat. After all, modern consumers need new features without any planned/unplanned downtimes, glitches, or other disruptions.
Observability enables developers and engineers to find the perfect balance between innovation and prime performance. AI-powered observability develops a comprehensive understanding of systems, processes, and operations and implements a continuous learning cycle to stay above baseline performance metrics. Anything that isn’t coherent with the high-performance standards gets scrutinized and improved upon immediately.
With observability, businesses are more confident than ever to deliver the most meaningful and engaging digital experiences. And while all these benefits are great, there’s still one question left to answer: What are you waiting for?